Indexación del Código Base
La Indexación del Código Base habilita la búsqueda semántica de código en todo tu proyecto usando embeddings de IA. En lugar de buscar coincidencias de texto exactas, comprende el significado de tus consultas, ayudando a AI Cockpit a encontrar código relevante incluso cuando no conoces nombres de funciones o ubicaciones de archivos específicos.
Qué Hace
Cuando está habilitado, el sistema de indexación:
- Analiza tu código usando Tree-sitter para identificar bloques semánticos (funciones, clases, métodos)
- Crea embeddings de cada bloque de código usando modelos de IA
- Almacena vectores en una base de datos Qdrant para búsqueda rápida por similitud
- Proporciona la herramienta
codebase_searcha AI Cockpit para el descubrimiento inteligente de código
Esto permite consultas en lenguaje natural como "lógica de autenticación de usuarios" o "manejo de conexión a base de datos" para encontrar código relevante en todo tu proyecto.
Beneficios Clave
- Búsqueda Semántica: Encuentra código por significado, no solo por palabras clave
- Comprensión Mejorada de la IA: AI Cockpit puede comprender y trabajar mejor con tu código base
- Descubrimiento entre Proyectos: Busca en todos los archivos, no solo en los que están abiertos
- Reconocimiento de Patrones: Localiza implementaciones similares y patrones de código
Requisitos de Configuración
Proveedor de Embeddings
Elige una de estas opciones para generar embeddings:
OpenAI (Recomendado)
- Requiere clave de API de OpenAI
- Admite todos los modelos de embedding de OpenAI
- Predeterminado:
text-embedding-3-small - Procesa hasta 100,000 tokens por lote
Gemini
- Requiere clave de API de Google AI
- Admite modelos de embedding de Gemini incluyendo
gemini-embedding-001 - Alternativa rentable a OpenAI
- Embeddings de alta calidad para comprensión de código
Ollama (Local)
- Requiere instalación local de Ollama
- Sin costos de API ni dependencia de internet
- Admite cualquier modelo de embedding compatible con Ollama
- Requiere configuración de URL base de Ollama
Base de Datos Vectorial
Qdrant es necesario para almacenar y buscar embeddings:
- Local:
http://localhost:6333(recomendado para pruebas) - Nube: Qdrant Cloud o instancia autoalojada
- Autenticación: Clave de API opcional para implementaciones seguras
Configurar Qdrant
Configuración Local Rápida
Usando Docker:
docker run -p 6333:6333 qdrant/qdrant
Usando Docker Compose:
version: "3.8"
services:
qdrant:
image: qdrant/qdrant
ports:
- "6333:6333"
volumes:
- qdrant_storage:/qdrant/storage
volumes:
qdrant_storage:
Implementación en Producción
Para uso en equipo o producción:
- Qdrant Cloud - Servicio gestionado
- Autoalojado en AWS, GCP o Azure
- Servidor local con acceso a red para compartir en equipo
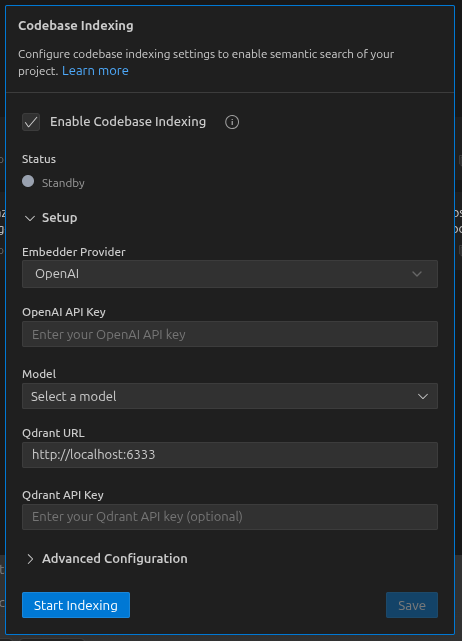
Configuración
- Abre la configuración de AI Cockpit (ícono )
- Navega a la sección Indexación del Código Base
- Habilita "Habilitar Indexación del Código Base" usando el interruptor
- Configura tu proveedor de embeddings:
- OpenAI: Ingresa la clave de API y selecciona el modelo
- Gemini: Ingresa la clave de API de Google AI y selecciona el modelo de embedding
- Ollama: Ingresa la URL base y selecciona el modelo
- Establece la URL de Qdrant y la clave de API opcional
- Configura los Resultados Máximos de Búsqueda (predeterminado: 20, rango: 1-100)
- Haz clic en Guardar para iniciar la indexación inicial
Interruptor de Habilitar/Deshabilitar
La función de indexación del código base incluye un interruptor conveniente que te permite:
- Habilitar: Comenzar a indexar tu código base y hacer disponible la herramienta de búsqueda
- Deshabilitar: Detener la indexación, pausar la observación de archivos y deshabilitar la funcionalidad de búsqueda
- Preservar Configuración: Tu configuración permanece guardada al desactivar
Este interruptor es útil para deshabilitar temporalmente la indexación durante trabajo de desarrollo intensivo o cuando se trabaja con bases de código sensibles.
Comprender el Estado del Índice
La interfaz muestra el estado en tiempo real con indicadores de color:
- En espera (Gris): No está en ejecución, esperando configuración
- Indexando (Amarillo): Procesando archivos actualmente
- Indexado (Verde): Actualizado y listo para búsquedas
- Error (Rojo): Estado de fallo que requiere atención
Cómo se Procesan los Archivos
Análisis Inteligente de Código
- Integración con Tree-sitter: Usa análisis AST para identificar bloques de código semánticos
- Soporte de Lenguajes: Todos los lenguajes admitidos por Tree-sitter
- Soporte de Markdown: Soporte completo para archivos markdown y documentación
- Alternativa: Fragmentación basada en líneas para tipos de archivos no admitidos
- Tamaño de Bloque:
- Mínimo: 100 caracteres
- Máximo: 1,000 caracteres
- Divide funciones grandes de forma inteligente
Filtrado Automático de Archivos
El indexador excluye automáticamente:
- Archivos binarios e imágenes
- Archivos grandes (>1MB)
- Repositorios Git (carpetas
.git) - Dependencias (
node_modules,vendor, etc.) - Archivos que coincidan con patrones de
.gitignorey.kilocodeignore
Actualizaciones Incrementales
- Observación de Archivos: Monitorea el espacio de trabajo para detectar cambios
- Actualizaciones Inteligentes: Solo reprocesa los archivos modificados
- Caché Basado en Hash: Evita reprocesar contenido sin cambios
- Cambio de Rama: Maneja automáticamente los cambios de rama de Git
Mejores Prácticas
Selección de Modelo
Para OpenAI:
text-embedding-3-small: Mejor equilibrio entre rendimiento y costotext-embedding-3-large: Mayor precisión, 5 veces más costosotext-embedding-ada-002: Modelo heredado, menor costo
Para Ollama:
mxbai-embed-large: El modelo de embedding más grande y de mayor calidad.nomic-embed-text: Mejor equilibrio entre rendimiento y calidad de embedding.all-minilm: Modelo compacto con menor calidad pero rendimiento más rápido.
Consideraciones de Seguridad
- Claves de API: Almacenadas de forma segura en el almacenamiento cifrado de VS Code
- Privacidad del Código: Solo se envían pequeños fragmentos de código para embedding (no archivos completos)
- Procesamiento Local: Todo el análisis ocurre localmente
- Seguridad de Qdrant: Usa autenticación para implementaciones en producción
Limitaciones Actuales
- Tamaño de Archivo: Máximo 1MB por archivo
- Espacio de Trabajo Único: Un espacio de trabajo a la vez
- Dependencias: Requiere servicios externos (proveedor de embeddings + Qdrant)
- Cobertura de Lenguajes: Limitado a los lenguajes admitidos por Tree-sitter para un análisis óptimo
Usar la Función de Búsqueda
Una vez indexado, AI Cockpit puede usar la herramienta codebase_search para encontrar código relevante:
Consultas de Ejemplo:
- "¿Cómo se maneja la autenticación de usuarios?"
- "Configuración de conexión a base de datos"
- "Patrones de manejo de errores"
- "Definiciones de endpoints de API"
La herramienta proporciona a AI Cockpit:
- Fragmentos de código relevantes (hasta el límite máximo de resultados configurado)
- Rutas de archivos y números de línea
- Puntuaciones de similitud
- Información contextual
Configuración de Resultados de Búsqueda
Puedes controlar el número de resultados de búsqueda devueltos ajustando la configuración de Resultados Máximos de Búsqueda:
- Predeterminado: 20 resultados
- Rango: 1-100 resultados
- Rendimiento: Los valores más bajos mejoran la velocidad de respuesta
- Exhaustividad: Los valores más altos proporcionan más contexto pero pueden ralentizar las respuestas
Privacidad y Seguridad
- El código permanece local: Solo se envían pequeños fragmentos de código para embedding
- Los embeddings son numéricos: No son representaciones legibles por humanos
- Almacenamiento seguro: Claves de API cifradas en el almacenamiento de VS Code
- Opción local: Usa Ollama para procesamiento completamente local
- Control de acceso: Respeta los permisos de archivos existentes
Mejoras Futuras
Mejoras planificadas:
- Proveedores de embeddings adicionales
- Indexación de múltiples espacios de trabajo
- Opciones mejoradas de filtrado y configuración
- Capacidades de compartir en equipo
- Integración con la búsqueda nativa de VS Code